
W dzisiejszych czasach, kiedy czytać potrafi prawie każdy (choć grono zdolnych do czytania ze zrozumieniem jest już nieco elitarne), umiejętność ta może się wydawać czymś banalnym. Trzeba jednak uzmysłowić sobie, że dawniej czytanie było znacznie trudniejsze. W zasadzie jeszcze do XIV wieku w większości języków stosowano zapis ciągły bez znaków interpunkcyjnych (łac. scriptura continua). Czytanie takiego tekstu po cichu było praktycznie niemożliwe.
Z drugiej jednak strony do czasu rozpowszechnienia druku dostępność książek i tanich materiałów piśmiennych była na tyle ograniczona, że większość ludzi umiejętności czytania i pisania nie potrzebowała. Owszem, zapisywano ważne dokumenty, tym jednak zajmowali się specjalni rzemieślnicy – oficjalni pisarze, zwani też skrybami. Przez całe wieki, a nieledwie i tysiąclecia, skrybom wiodło się całkiem nieźle; zainteresowanych dalszymi informacjami odsyłam tu:
Kwestię czytania dodatkowo komplikowało to, że kierunek zapisywania tekstu nie był stały! Dziś w większości języków piszemy od lewej do prawej – w tych mianowicie, które posługują się alfabetem opartym na alfabecie łacińskim. Natomiast języki posługujące się alfabetami wywodzącymi się od alfabetu fenickiego mają odwrotny kierunek zapisu, od prawej do lewej. Tak jest m.in. w języku aramejskim, hebrajskim, arabskim, perskim… Podobnie było z językiem staroangielskim, kiedy zapisywano go alfabetem runicznym zwanym futhark.
Jeszcze inaczej wygląda tradycyjny zapis w języku chińskim albo japońskim: znaki stawia się pionowymi kolumnami, poczynając od prawej krawędzi kartki. Przez to np. książki japońskie są „odwrotne”, tzn. zaczynają się od tej strony, po której książki w kulturze zachodniej się kończą. Tak są wydawane także mangi poza Japonią, co mnie na przykład poważnie utrudnia ich czytanie.
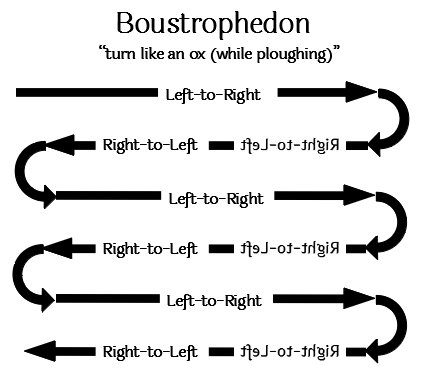
Ale to dziś, natomiast dawniej przez pewną część historii cywilizacji śródziemnomorskiej stosowano zapis naprzemienny! Gdy tekst pisany od lewej dochodził do prawego krawędzi strony, piszący nie przeskakiwał z powrotem do lewej krawędzi, tylko schodził wiersz niżej i pisał od prawej do lewej, przy lewej krawędzi znowu zawracał, przy prawej ponownie i tak dalej. W ten sposób tekst tworzył swoisty „zygzak” na stronie, co nazywało się bustrofedon – słowo to pochodzi z greki i oznacza mniej więcej „zawracający wół”, gdyż zmienny kierunek pisania przypominał sposób poruszania się wołu zaprzężonego do pługa i zawracającego w przeciwnym kierunku zawsze po dojściu do krańca oranego pola.
Żeby było jeszcze trudniej, w tamtych czasach nie znano też rozróżnienia wielkich i małych liter! Teksty zapisywano samymi wersalikami, czyli pismem zwanym majuskułą. Nic dziwnego, że czytanie nie było rozpowszechnioną umiejętnością – po prostu większość ludzi miała wtedy na głowie dosyć innych spraw, żeby jeszcze zawracać sobie głowę czymś tak skomplikowanym, a i niespecjalnie praktycznym. Na szczęście potem, krok po kroku, sytuacja się zmieniła.
Zaczęło się jeszcze w starożytności, kiedy to wymyślono pierwsze znaki interpunkcyjne. Na pomysł ten wpadł niejaki Arystofanes z Bizancjum, bibliotekarz w Bibliotece Aleksandryjskiej, pragnący ułatwić lekturę greckich tekstów. Czytanie na głos wymagało pauz w celu nabierania oddechu, więc Arystofanes wymyślił system kropek między wyrazami. Kropka u góry wiersza oznaczała koniec myśli, czyli była odpowiednikiem naszej kropki stawianej na końcu zdania. Kropka pośrodku wiersza wskazywała dodatkowe miejsce na wdech, odpowiadała zatem w pewnym stopniu naszej pauzie. Natomiast kropka u dołu wiersza stawiana była w miejscu oznaczającym dopełnienie myśli, więc można powiedzieć, że stanowiła odpowiednik przecinka.
Nie wszyscy stali się zwolennikami takich pomysłów, więc system kropek stosowany był z przerwami (zastosowano go np. w rękopisie Biblii z IV wieku n.e., zwanym Codex Sinaiticus). W międzyczasie (VII-IX wiek) w łacinie pojawiła się spacja będąca pustym miejscem między słowami, jednak rozpowszechniała się bardzo powoli. Wiele tekstów spisanych po łacinie nawet w późnym średniowieczu nie zawierało spacji. Dopiero w renesansie przyjęto ją powszechnie we Włoszech i Francji, pod koniec XVI wieku na terenach Bizancjum, a w językach słowiańskich – za pośrednictwem cyrylicy w XVII wieku.
Znacznie wcześniej wymyślono podział tekstu na akapity (tradycyjnie, już w starożytnej Grecji). Dziś, zwłaszcza w druku (na stronach internetowych znacznie rzadziej), początek nowego akapitu zaczyna się tzw. wcięciem akapitowym. Początek pierwszego wiersza jest przesunięty w prawo o pewien odcinek (z automatu na ogół o ćwierć cala). Wszystkie edytory tekstu godne tego miana mają funkcję umożliwiającą wstawianie takiego wcięcia.
Pierwotnie jednak początek nowego akapitu oznaczany był specjalnym znakiem – najpierw był to paragraphos, kreska lub łuk stawiany na marginesie w miejscu rozpoczęcia rozdziału. Potem rolę tę przejęła litera K, od łacińskiego kaput czyli „głowa” (tak, Rzymianie początkowo nie używali C, a pochodzącego od Etrusków K). Dalsza ewolucja obejmowała zmianę wyglądu, przez C aż do znaku ¶, który dziś można zobaczyć na końcu akapitu w tekście pisanym na komputerze, gdy włączymy wyświetlanie znaków niedrukowanych. W ten sposób promotor może sprawdzić, ile zbędnych pustych wierszy wstawił do tekstu student, żeby jego praca dyplomowa miała więcej stron…
No dobrze, ale skąd się wzięło wcięcie akapitowe? Otóż znak ¶ traktowano tak samo jak inicjał, od którego zwykle wtedy rozpoczynało się już nowy rozdział. A inicjały były w istocie małymi rysuneczkami, których wykonanie wymagało użycia kolorowych farb i zajmowało o wiele więcej czasu niż napisanie zwykłych liter. Zatem podczas przepisywania ksiąg najpierw szybko wpisywano sam tekst, a inicjały i znaki akapitu jedynie zaznaczano szkicowo albo wręcz zostawiano puste miejsca do późniejszego uzupełnienia. I o ile nadzorcy skrybów pilnowali zdobienia inicjałów – których w sumie nie było w tekście tak dużo – o tyle znaki akapitu, znacznie liczniejsze, z czasem zaczęły być pomijane i pozostało po nich puste miejsce!
Te i wiele podobnych niepraktycznych informacji zawiera książka Keitha Houstona Ciemne typki, wydana w 2015 roku (wznowiona w 2020) przez krakowskie wydawnictwo Karakter (a przygotowana, co warto podkreślić, bardzo starannie, w bardzo dobrym przekładzie Magdaleny Komorowskiej, pięknej twardej oprawie, z dobrej jakości ilustracjami i stosowną pieczołowitością typograficzną). Co prawda czasem autor nadmiernie rozwodzi się nad niektórymi dziwnymi pomysłami Anglosasów (kto słyszał o interrobangu? – obrazek poniżej), ale ogólnie rzecz jest interesująca. I zawiera mnóstwo ciekawostek.

Wszyscy znamy Asteriksa, prawda? I jego kumpla Obeliksa oczywiście też. A skąd się wzięły ich imiona? René Goscinny, twórca tych postaci (podobnie jak Lucky Luke’a) wymyślił sobie bohaterów o imionach Asteriks i Obeliks, urobionych na wzór Wercyngetoryksa (wodza pokonanego przez Juliusza Cezara podczas wojen galijskich), od znaków typograficznych: asterysku * i obelisku † lub ‡ (po angielsku dagger i double dagger). To, że Obeliks jest dostawcą menhirów zwanych przez niektórych obeliskami, to już sprawa uboczna.
Jedną ze smacznych anegdot w Ciemnych typkach jest wspomniana na marginesie historyjka o zarzuceniu stosowania tzw. długiego s w angielszczyźnie, które nadal można znaleźć w znakach Unicode: ʃ. Wygląda ono bardzo podobnie do f, zwłaszcza w kursywie: ʃ i f. Otóż pod koniec XVIII wieku angielski drukarz John Bell składał kursywą kolejne wydanie Burzy Szekspira, gdzie znajduje się m.in. passus Where the bee sucks, there suck I. W wersji z długim s fragment wyglądał tak: Where the bee ʃucks, there ʃuck I. No to już chyba jasne, dlaczego zrezygnowano z tego znaku.
[źródła: W.Kopaliński, Opowieści o rzeczach powszednich; K.Houston Ciemne typki. Sekretne życie znaków typograficznych; https://www.thesaurus.com/e/writing/righttoleft/; What is Boustrophedon? – BibleQuestions.info]